readelf -S を簡易実装してセクションヘッダを理解する
目次
注意
readelf 実装 で検索すると未だに一番上に出てきてしまっているので注意.
これはelfについて全然詳しくない時期に書いたものです.
一応入門的内容についてまとめたものがあるので,
よろしければそちらを.
概要
こちらの記事の続きです。
一応今回でreadelfは最終回になると思います。
今回はセクションヘッダを解析するコードを書きました。
ソースコードはこちらに。
elfパッケージを見てくださいね。
https://github.com/Drumato/goccgithub.com
前半についてですが、大体の流れは前回と同じなので、
前半は特に解説せず実装だけをしていきます。
StringTableについては別途解説が必要だと思うので、
後々解説を加えます。
前提:セクションヘッダとは?
前回と同じくこちらの記事を参照して頂ければと思います。
http://caspar.hazymoon.jp/OpenBSD/annex/elf.htmlcaspar.hazymoon.jp
こちらの記事を引用させていただきます。
セクションヘッダテーブルは、全てのファイルのセクションの位置決定を可能とします。
各セクションにはプログラムコードや読取り専用データ、読書き可能データ、再配置エントリー、
シンボル等の情報が種類ごとに格納されています。
セクションヘッダについてもプログラムヘッダテーブルと同じく、
ELFヘッダを解析することで位置がわかるようになっています。
実際にELFヘッダを見てみましょう。
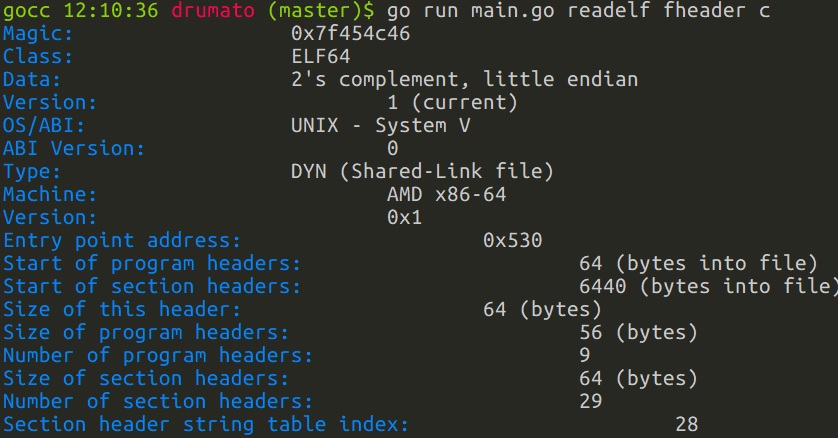
セクションヘッダを解析する上で重要なのは、
Start of section headersSize of section headersNumber of section headersSection header string table index
になります。
本題1:実装
String Tableについては後述するので、
まずはセクションヘッダの構造体を定義してみます。
type SectionHeader struct { Name Elf64_Word //セクション名 Type Elf64_Word //セクションの内容と意味 Flags Elf64_Xword //アクセス制御等のビットフラグ Addr Elf64_Addr Offset Elf64_Off //ファイル先頭からのオフセット Size Elf64_Xword //セクションのバイト長 Link Elf64_Word Info Elf64_Word Alignment Elf64_Xword //アドレスのアラインメント EntrySize Elf64_Xword //固定長のエントリーテーブル }
あとは渡されたバイト列を順にこのヘッダに格納していくだけです。
func AssignSectionHeader(binaries []byte, sHOff Elf64_Off, sHNum, sHSize Elf64_Half) []SectionHeader { binaries = binaries[int(sHOff):] shdrs := make([]SectionHeader, sHNum) for i := range shdrs { shdrs[i].Name = Elf64_Word(binary.LittleEndian.Uint32([]byte{binaries[0], binaries[1], binaries[2], binaries[3], 0x00, 0x00, 0x00, 0x00})) shdrs[i].Type = Elf64_Word(binary.LittleEndian.Uint32([]byte{binaries[4], binaries[5], binaries[6], binaries[7], 0x00, 0x00, 0x00, 0x00})) shdrs[i].Flags = Elf64_Xword(binary.LittleEndian.Uint64(binaries[8:16])) shdrs[i].Addr = Elf64_Addr(binary.LittleEndian.Uint64(binaries[16:24])) shdrs[i].Offset = Elf64_Off(binary.LittleEndian.Uint64(binaries[24:32])) shdrs[i].Size = Elf64_Xword(binary.LittleEndian.Uint64(binaries[32:40])) shdrs[i].Link = Elf64_Word(binary.LittleEndian.Uint32([]byte{binaries[40], binaries[41], binaries[42], binaries[43], 0x00, 0x00, 0x00, 0x00})) shdrs[i].Info = Elf64_Word(binary.LittleEndian.Uint32([]byte{binaries[44], binaries[45], binaries[46], binaries[47], 0x00, 0x00, 0x00, 0x00})) shdrs[i].Alignment = Elf64_Xword(binary.LittleEndian.Uint64(binaries[48:56])) shdrs[i].EntrySize = Elf64_Xword(binary.LittleEndian.Uint64(binaries[56:64])) binaries = binaries[int(sHSize):] } return shdrs }
出力する際には定数に応じて出力内容を変化させていきます。
const ( SHT_NULL = 0 SHT_PROGBITS = 1 SHT_SYMTAB = 2 SHT_STRTAB = 3 SHT_RELA = 4 SHT_HASH = 5 SHT_DYNAMIC = 6 SHT_NOTE = 7 SHT_NOBITS = 8 SHT_REL = 9 SHT_SHLIB = 10 SHT_DYNSYM = 11 SHT_INIT_ARRAY = 14 SHT_FINI_ARRAY = 15 SHT_PREINIT_ARRAY = 16 SHT_GROUP = 17 SHT_SYNTAB_SHNDX = 18 SHT_NUM = 19 SHT_GNU_HASH = 0x6ffffff6 SHT_GNU_VERNEED = 0x6ffffffe SHT_GNU_VERSYM = 0x6fffffff SHT_LOPROC = 0x70000000 SHT_HIPROC = 0x7fffffff SHT_LOUSER = 0x80000000 SHT_HIUSER = 0xffffffff /* special section indexes */ SHN_UNDEF = 0 SHN_LORESERVE = 0xff00 SHN_LOPROC = 0xff00 SHN_HIPROC = 0xff1f SHN_LIVEPATCH = 0xff20 SHN_ABS = 0xfff1 SHN_COMMON = 0xfff2 SHN_HIRESERVE = 0xffff ) const ( /* sh_flags */ SHF_WRITE = (1 << 0) /* Writable */ SHF_ALLOC = (1 << 1) /* Occupies memory during execution */ SHF_EXECINSTR = (1 << 2) /* Executable */ SHF_MERGE = (1 << 4) /* Might be merged */ SHF_STRINGS = (1 << 5) /* Contains nul-terminated strings */ SHF_INFO_LINK = (1 << 6) /* `sh_info' contains SHT index */ SHF_LINK_ORDER = (1 << 7) /* Preserve order after combining */ SHF_OS_NONCONFORMING = (1 << 8) /* Non-standard OS specific handling required */ SHF_GROUP = (1 << 9) /* Section is member of a group. */ SHF_TLS = (1 << 10) /* Section hold thread-local data. */ SHF_COMPRESSED = (1 << 11) /* Section with compressed data. */ SHF_MASKOS = 0x0ff00000 /* OS-specific. */ SHF_MASKPROC = 0xf0000000 /* Processor-specific */ SHF_ORDERED = (1 << 30) /* Special ordering requirement (Solaris). */ SHF_EXCLUDE = (1 << 31) /* Section is excluded unless referenced or allocated (Solaris).*/ ) func parseSType(sType Elf64_Word) string { switch sType { case SHT_NULL: return "NULL" case SHT_PROGBITS: return "PROGBITS" case SHT_SYMTAB: return "SYMTAB" case SHT_STRTAB: return "STRTAB" case SHT_RELA: return "RELA" case SHT_HASH: return "HASH" case SHT_DYNAMIC: return "DYNAMIC" case SHT_NOTE: return "NOTE" case SHT_NOBITS: return "NOBITS" case SHT_REL: return "REL" case SHT_SHLIB: return "SHLIB" case SHT_DYNSYM: return "DYNSYM" case SHT_INIT_ARRAY: return "INIT_ARRAY" case SHT_FINI_ARRAY: return "FINI_ARRAY" /* case SHT_PREINIT_ARRAY: return "PREINIT_ARRAY" */ case SHT_GNU_HASH: return "GNU_HASH" /* case SHT_GROUP: return "GROUP" case SHT_SYMTAB_SHNDX: return "SYMTAB SECTION INDICES" case SHT_GNU_verdef: return "VERDEF" */ case SHT_GNU_VERNEED: return "VERNEED" case SHT_GNU_VERSYM: return "VERSYM" /* case 0x6ffffff0: return "VERSYM" case 0x6ffffffc: return "VERDEF" case 0x7ffffffd: return "AUXILIARY" case 0x7fffffff: return "FILTER" case SHT_GNU_LIBLIST: return "GNU_LIBLIST" */ default: return fmt.Sprintf("%#x", sType) } return "ILLEGAL" } func parseSFlags(flags Elf64_Xword) string { var flag string if flags&SHF_WRITE != 0 { flag += "W" } else { flag += " " } if flags&SHF_ALLOC != 0 { flag += "A" } else { flag += " " } if flags&SHF_EXECINSTR != 0 { flag += "X" } else { flag += " " } if flags&SHF_MERGE != 0 { flag += "M" } else { flag += " " } if flags&SHF_STRINGS != 0 { flag += "S" } else { flag += " " } if flags&SHF_INFO_LINK != 0 { flag += "I" } else { flag += " " } if flags&SHF_LINK_ORDER != 0 { flag += "L" } else { flag += " " } if flags&SHF_OS_NONCONFORMING != 0 { flag += "O" } else { flag += " " } if flags&SHF_GROUP != 0 { flag += "G" } else { flag += " " } if flags&SHF_TLS != 0 { flag += "T" } else { flag += " " } if flags&SHF_EXCLUDE != 0 { flag += "E" } else { flag += " " } if flags&SHF_COMPRESSED != 0 { flag += "C" } else { flag += " " } return flag }
実際に出力させる関数は、
func DumpSHeader(b []byte, shdrs []SectionHeader, header *ElfHeader) { fmt.Println("\nSection Headers:") t := tablewriter.NewWriter(os.Stdout) //Name Type Address Offset Size EntSize Flags Link Info Align t.Append( []string{ fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Nr"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Name"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Type"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Address"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Offset"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Size"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("EntSize"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Flags"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Link"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Info"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Align"))), }) var cnt int for _, shdr := range shdrs { t.Append([]string{ fmt.Sprintf("[%d]", cnt), dumpStringTable(b, shdrs, header, shdr.Name), parseSType(shdr.Type), fmt.Sprintf("%#x", shdr.Addr), fmt.Sprintf("%#x", shdr.Offset), fmt.Sprintf("%#x", shdr.Size), fmt.Sprintf("%#x", shdr.EntrySize), parseSFlags(shdr.Flags), fmt.Sprintf("%d", shdr.Link), fmt.Sprintf("%d", shdr.Info), fmt.Sprintf("%d", shdr.Alignment), }) cnt++ } t.Render() }
です。
出力は以下の様になります。
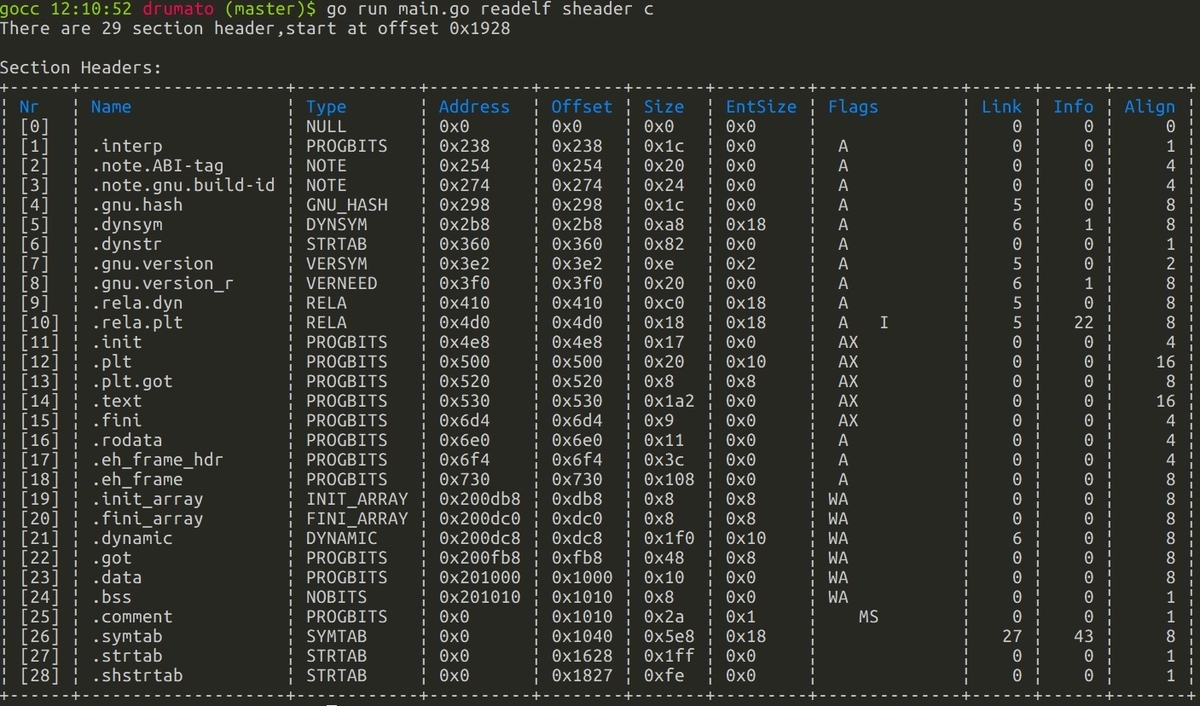
本題2:セクション名のテーブルについて
先程の画像には、
.interp,.init等、
セクション名が表示されていた と思います。
しかしバイト列をそのまま読み込んでも、
この文字列は格納されません。
実際に出力してみましょう。
セクションヘッダのうち、
SectionHeader.Nameを出力してみます。
![]()
謎の数値が出力されました。
これは何を表しているのでしょうか…?
先程示した、ELFヘッダの出力をもう一度見返してみましょう。
このSection header string table indexという項目は、
セクションヘッダを格納するStringTableのインデックスを示しています。
StringTableというのは、
\0 . s y m t a b \0 . s t r t a b \0 . s h s t r t a b \0 . i n t e r p \0 . n o t e . A B I - t a g \0 . g n u . h a s h \0 . d y n s y m \0 . d y n s t r \0 . g n u . v e r s i o n \0 . g n u . v e r s i o n _ r \0 . r e l a . d y n \0 . r e l a . p l t \0 . i n i t \0 . t e x t \0 . f i n i \0 . r o d a t a \0 . e h _ f r a m e _ h d r \0 . e h _ f r a m e \0 . i n i t _ a r r a y \0 . f i n i _ a r r a y \0 . j c r \0 . d y n a m i c \0 . g o t \0 . g o t . p l t \0 . d a t a \0 . b s s \0 . c o m m e n t \0
ELF入門 - 情弱ログより引用
のようなものです。
NULLバイトで区切られたセクション名が格納されています。
これ自体が一つのセクションに格納されています。
先程のELFヘッダにあった項目は、
このStringTableがどのセクションヘッダに格納されているかを示すインデックスというわけです。
セクション名を解析するためには、
ElfHeader.SectionNumber(先述したStringTableを示すインデックス)を取り出す- バイト列から
SectionHeader.Nameの位置にある文字列を取り出す- 具体的には
SectionHeader.NameからNULLバイトまで
- 具体的には
という流れを踏みます。
あとはコードに起こすだけです。
func dumpStringTable(b []byte, shdrs []SectionHeader, header *ElfHeader, sName Elf64_Word) string { stringTable = shdrs[header.SectionNumber] b = b[int(stringTable.Offset)+int(sName):] var bys []byte var ret string for _, bt := range b { if bt == 0 { fmt.Println(string(bys)) ret = string(bys) break } bys = append(bys, bt) } return ret }
これでセクションヘッダの解析が出来たことになります。
総評
セクションヘッダの解析までが終わりました。
後はこのセクションヘッダから各セクションの解析が終われば、
ELFバイナリの出力が出来るようになったと言えそうです。