readelf -lを簡易実装してELFフォーマットの理解を深める。
目次
注意
readelf 実装 で検索すると未だに一番上に出てきてしまっているので注意.
これはelfについて全然詳しくない時期に書いたものです.
一応入門的内容についてまとめたものがあるので,
よろしければそちらを.
概要
こちらの記事の続きです
ELFヘッダのあとは、
プログラムヘッダの解析 に移るのが自然な流れだと思います。
今回も ソースコードベース で見ていくことで、
バイナリに慣れていない人にも理解できる記事を目指します。
GitHubを参照しながら読み進めて頂ければと思います。
https://github.com/Drumato/gocc/tree/master/elfgithub.com
前提:プログラムヘッダテーブルとは?
私の記事を読む前に、
こちらの記事を読んでおくことをおすすめします。
/usr/include/elf.hの内容を解説する記事は多いですが、
構造体の各メンバ・ヘッダ情報の意味についてここまで詳しく解説している日本語の記事はこれ以外ないかも。
こちらの記事に記載されている情報を参考にしながら、
簡単に前提知識をお話しておきます。
プログラムヘッダテーブルとは、
セグメント情報を格納した配列 です。
OSがプロセス生成して実行するようなプログラムには
必ずこのプログラムヘッダテーブルが存在しています。
具体的にどんな情報が入っているかを紹介します。
- セグメント情報
- どのようにこのセグメントを解釈すべきかを識別する
- セグメントのファイル上でのオフセット
- セグメントにマッピングされた仮想アドレス
- 物理アドレッシングのシステム上で用いるためのフィールド
- セグメントのファイルイメージ上のバイト数
- セグメントのメモリイメージ上のバイト数
- セグメントの属性を示すフラグ
- セグメントのアラインメント
前回の記事で説明したとおり、
ELFヘッダには プログラムヘッダテーブル (を参照するため)の情報が格納されています。
実際にELFヘッダを解析して、
プログラムヘッダテーブルを参照するための情報を見てみましょう。
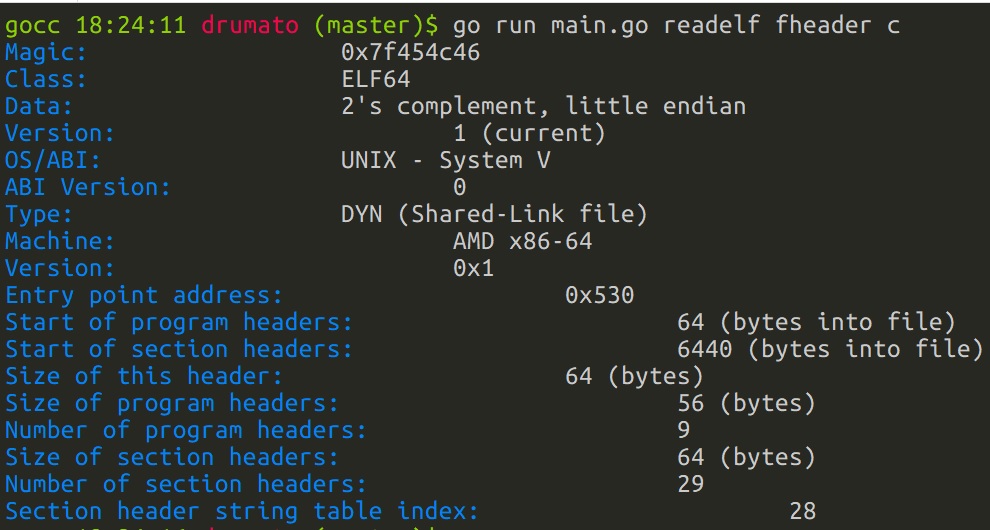
今回見たいのは、
Start of program headersSize of program headersNumber of program headers- (
size of this header)- もしELFヘッダが64バイトでなければ考慮する必要がある
- 普段は特に関係ない
です。
これらはそれぞれ、
- プログラムヘッダテーブルが始まる場所( オブジェクトファイル上で)
- プログラムヘッダテーブルのサイズ( これは 1配列要素 を示す)
- プログラムヘッダの数
を表します。
プログラムヘッダテーブルを解析するには、
これら情報を活用する必要があります。
逆に言えば、
ELFヘッダを見ればプログラムヘッダテーブルがわかる ということです。
本題
コードリーディングで情報集め
まずはLinuxのヘッダファイルを参照して、
コーディングの為の情報を集めます。
/usr/include/elf.hでは、
プログラムヘッダの構造体が定義されています。
typedef struct elf32_phdr{ Elf32_Word p_type; Elf32_Off p_offset; Elf32_Addr p_vaddr; Elf32_Addr p_paddr; Elf32_Word p_filesz; Elf32_Word p_memsz; Elf32_Word p_flags; Elf32_Word p_align; } Elf32_Phdr; typedef struct elf64_phdr { Elf64_Word p_type; Elf64_Word p_flags; Elf64_Off p_offset; /* Segment file offset */ Elf64_Addr p_vaddr; /* Segment virtual address */ Elf64_Addr p_paddr; /* Segment physical address */ Elf64_Xword p_filesz; /* Segment size in file */ Elf64_Xword p_memsz; /* Segment size in memory */ Elf64_Xword p_align; /* Segment alignment, file & memory */ } Elf64_Phdr;
先程列挙した情報がメンバとして定義されているのがわかると思います。
次に、readelfを参照し、
どのように出力すればいいのかを確認します。
を見てみましょう。
今回も
の記事でやったように、
- オプション引数を解析する
parse_args()を見る - 立ったフラグ(今回は
do_segments)によって処理・フローが変わる部分を見る
という流れでコードを読みます。
巨大なソースコードの場合、
(優れたサービス・ソフトウェアであれば) 参照しやすい・理解しやすいコード設計に尽力しているはずです。
今回はフラグという管理方法をとっていますね。
static void parse_args (Filedata * filedata, int argc, char ** argv) { //省略 case 'l': do_segments = TRUE; break; //省略2 }
見つけました。
do_segmentsでgrepをかけます。
当該フラグによって出力される部分
を見つけ、
内容を読んでいきます。
とても長いので、
今回実装した部分のみを抜き出して紹介します。
if (do_segments) { if (filedata->file_header.e_phnum > 1) printf (_("\nProgram Headers:\n")); else printf (_("\nProgram Headers:\n")); if (is_32bit_elf) printf( _(" Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align\n")); else if (do_wide) printf(_(" Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align\n")); else { printf(_(" Type Offset VirtAddr PhysAddr\n")); printf(_(" FileSiz MemSiz Flags Align\n")); } } for (i = 0, segment = filedata->program_headers; i < filedata->file_header.e_phnum; i++, segment++) { if (do_segments) { printf (" %-14.14s ", get_segment_type (filedata, segment->p_type)); if (is_32bit_elf) { printf ("0x%6.6lx ", (unsigned long) segment->p_offset); printf ("0x%8.8lx ", (unsigned long) segment->p_vaddr); printf ("0x%8.8lx ", (unsigned long) segment->p_paddr); printf ("0x%5.5lx ", (unsigned long) segment->p_filesz); printf ("0x%5.5lx ", (unsigned long) segment->p_memsz); printf ("%c%c%c ", (segment->p_flags & PF_R ? 'R' : ' '), (segment->p_flags & PF_W ? 'W' : ' '), (segment->p_flags & PF_X ? 'E' : ' ')); printf ("%#lx", (unsigned long) segment->p_align); } } }
出力の形式等は大体わかりました。
あとは愚直に実装していくだけです。
実装
今回は
- 構造体の定義
- 構造体のメンバをバイト毎に定義
- 出力関数の定義
という順番です。
これも前回と一緒ですね。
type ProgramHeader struct { Type Elf64_Word Flags Elf64_Word Offset Elf64_Off VirtualAddr Elf64_Addr PhysicalAddr Elf64_Addr SegmentSize Elf64_Xword MemorySize Elf64_Xword Alignment Elf64_Xword }
構造体のメンバは分かりやすいように長めにしています。
main関数で読み込んだファイルのバイト列を渡し、
解析関数にぶっこんでいます。
b, err := elf.Prepare() //ファイルを読み込んでバイト列を返す if err != nil { return err } header := elf.AssignHeader(b[:64]) //ELFヘッダを宣言 pHeaders := elf.AssignProgramHeader( b, header.ProgramHeader, header.ProgramHeaderNum, header.ProgramHeaderSize ) //プログラムヘッダ解析に必要な情報を渡している fmt.Printf("Elf file type is %s\n", elf.ParseFileType(header.FileType)) fmt.Printf("Entry point %#x\n", header.EntryPoint) fmt.Printf("There are %d program headers, starting at offset %d\n", header.ProgramHeaderNum, header.ProgramHeader) elf.DumpPHeader(pHeaders, header.MachineArchitecture) //出力関数
Goは実装がシンプルになっていいですね。
肝心な解析関数を見ていきましょう。
func AssignProgramHeader(binaries []byte, pHOff Elf64_Off, pHNum, pHSize Elf64_Half) []ProgramHeader { binaries = binaries[int(pHOff):] //プログラムヘッダテーブルの始まり以前は切り取る phdrs := make([]ProgramHeader, pHNum) for i := range phdrs { phdrs[i].Type = Elf64_Word(binary.LittleEndian.Uint32(binaries[0:4])) phdrs[i].Flags = Elf64_Word(binary.LittleEndian.Uint32(binaries[4:8])) phdrs[i].Offset = Elf64_Off(binary.LittleEndian.Uint64(binaries[8:16])) phdrs[i].VirtualAddr = Elf64_Addr(binary.LittleEndian.Uint32(binaries[16:24])) phdrs[i].PhysicalAddr = Elf64_Addr(binary.LittleEndian.Uint32(binaries[24:32])) phdrs[i].SegmentSize = Elf64_Xword(binary.LittleEndian.Uint64(binaries[32:40])) phdrs[i].MemorySize = Elf64_Xword(binary.LittleEndian.Uint64(binaries[40:48])) phdrs[i].Alignment = Elf64_Xword(binary.LittleEndian.Uint64(binaries[48:56])) binaries = binaries[int(pHSize):] //プログラムヘッダのサイズで切り取る } return phdrs }
これは愚直に代入しまくるだけなので簡単ですね。
あとは先述したように出力をしていくだけです。
出力には
を用いています。
キレイなので。
func DumpPHeader(phdrs []ProgramHeader, ma Elf64_Half) { t := tablewriter.NewWriter(os.Stdout) //ファイルディスクリプタを指定 fmt.Println("\nProgram Headers:") t.Append( []string{ fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Type"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Offset"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("VirtAddr"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("PhysAddr"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("FileSiz"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("MemSiz"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Flags"))), fmt.Sprintf("%s", aurora.Bold(aurora.Blue("Align"))), }) for _, phdr := range phdrs { t.Append( //バッファに格納する []string{ parsePType(phdr.Type), //出力が単純ではないので別で関数定義 fmt.Sprintf("%#x", phdr.Offset), fmt.Sprintf("%#x", phdr.VirtualAddr), fmt.Sprintf("%#x", phdr.PhysicalAddr), fmt.Sprintf("%#x", phdr.SegmentSize), fmt.Sprintf("%#x", phdr.MemorySize), ParseFlags(phdr.Flags), fmt.Sprintf("%#x", phdr.Alignment)}) } t.Render() //バッファをフラッシュして標準出力 }
parsePType,ParseFlagsも見せておきます。
const ( PT_NULL = 0 /* Program header table entry unused */ PT_LOAD = 1 /* Loadable program segment */ PT_DYNAMIC = 2 /* Dynamic linking information */ PT_INTERP = 3 /* Program interpreter */ PT_NOTE = 4 /* Auxiliary information */ PT_SHLIB = 5 /* Reserved */ PT_PHDR = 6 /* Entry for header table itself */ PT_TLS = 7 /* Thread-local storage segment */ PT_NUM = 8 /* Number of defined types */ PT_LOOS = 0x60000000 /* Start of OS-specific */ PT_GNU_EH_FRAME = 0x6474e550 /* GCC .eh_frame_hdr segment */ PT_GNU_STACK = 0x6474e551 /* Indicates stack executability */ PT_GNU_RELRO = 0x6474e552 /* Read-only after relocation */ PT_LOSUNW = 0x6ffffffa PT_SUNWBSS = 0x6ffffffa /* Sun Specific segment */ PT_SUNWSTACK = 0x6ffffffb /* Stack segment */ PT_HISUNW = 0x6fffffff PT_HIOS = 0x6fffffff /* End of OS-specific */ PT_LOPROC = 0x70000000 /* Start of processor-specific */ PT_HIPROC = 0x7fffffff /* End of processor-specific */ PF_R = 0x4 PF_W = 0x2 PF_X = 0x1 ) func parsePType(ptype Elf64_Word) string { switch ptype { case PT_NULL: return "NULL" case PT_LOAD: return "LOAD" case PT_DYNAMIC: return "DYNAMIC" case PT_INTERP: return "INTERP" case PT_NOTE: return "NOTE" case PT_SHLIB: return "SHLIB" case PT_PHDR: return "PHDR" case PT_TLS: return "TLS" case PT_GNU_EH_FRAME: return "GNU_EH_FRAME" case PT_GNU_STACK: return "GNU_STACK" case PT_GNU_RELRO: return "GNU_RELRO" default: return "NOT IMPLEMENTED YET" } return "ILLEGAL" } func ParseFlags(flags Elf64_Word) string { //ビットのAND演算で判定 var flag string if flags&PF_R != 0 { flag += "R" } else { flag += " " } if flags&PF_W != 0 { flag += "W" } else { flag += " " } if flags&PF_X != 0 { flag += "E" } else { flag += " " } return flag
お疲れ様でした!
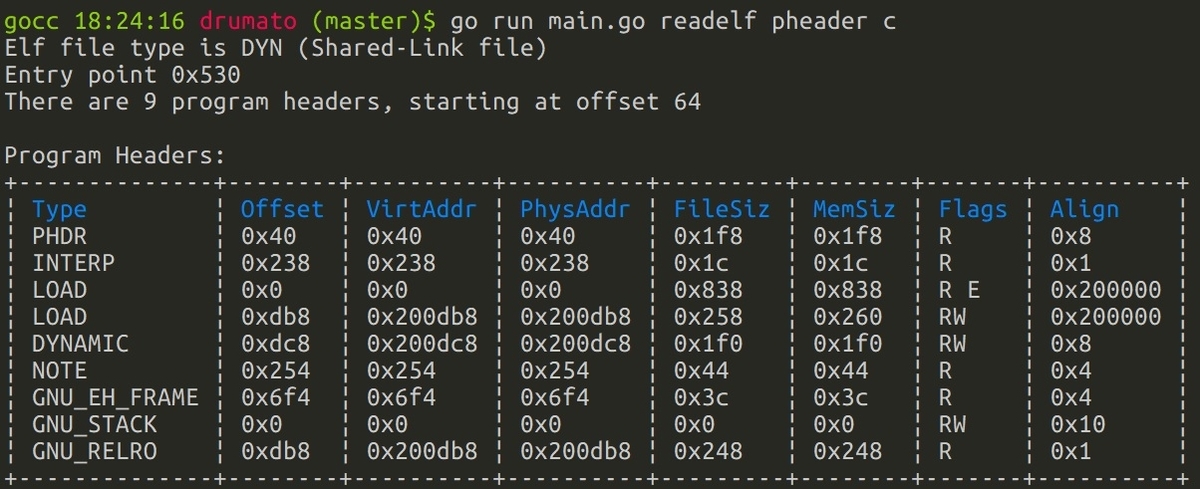
ここまで実装できれば、
下記のような出力が可能になります!
総評
プログラムヘッダテーブルの解析を実装することで、
ELFフォーマットの理解を深めました。